1.7. Using a segmentation to filter another¶
In some cases, the number of forms to be selectively included in or excluded from a segmentation is too large for using the Select widget. A typical example is the removal of “stopwords” from a text: in English for instance, although the list of such words is finite, it is too long to try to encode it by means of a regex (cf. an example of such a list).
The purpose of widget Intersect is precisely to solve that kind of problem. It takes two segmentations in input and lets the user include in or exclude from the first (source) segmentation those segments whose content is the same as that of a segment in the second (filter) segmentation. The widget’s basic interface is shown on figure 1 below).
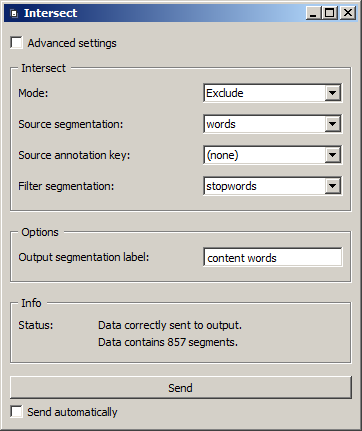
Figure 1: Interface of widget Intersect configured for stopword removal.
Similarly to widget Select, user must choose between modes Include and Exclude. The next step is to specify which incoming segmentation plays the role of the Source segmentation and the Filter segmentation. (Here again, we will ignore the Annotation key option for the time being.)
In order to try out the widget, set up a schema similar to the one shown on
figure 2 below). The first
instance of Text Field contains the text to process (for
instance the
Universal Declaration of Human Rights),
while the second instance, Text Field (1), contains the list of English
stopwords mentioned above. Both instances of Segment produce
a word segmentation with regex \w+; the only difference in their
configuration is the output segmentation label , i.e. words for Segment
and stopwords for Segment (1). Finally, the instance of
Intersect is configured as shown on
figure 1 above.
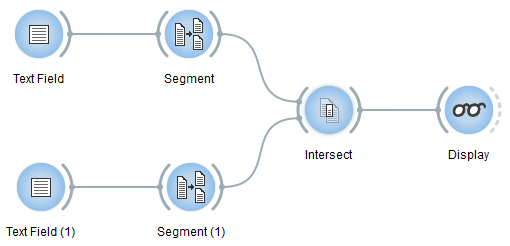
Figure 2: Example schema for removing stopword using widget Intersect .
The content of the first segments of the resulting segmentation is:
PREAMBLE
Whereas
recognition
inherent
dignity
equal
inalienable
rights
members
human
family
foundation
freedom
justice
peace
world
...
Exercise: Based on an instance of Text Field, produce a segmentation containing all words less than 4 letters long that appear at the beginning of each line, excluding I, you, he, she, we. (solution)
Solution:
Figure 3 below shows a possible solution. The 4 instances in the lower part of the schema (Text Field (1), Segment (1), Intersect, and Display) are configured as in figure 2 above–with Text Field (1) containing the list of pronouns to exclude.
The difference lies in the addition of a Segment instance in
the upper branch. In this branch, the first instance (Segment) produces a
segmentation into lines with regex .+ while Segment (2) extracts the
first word of each line, provided it is shorter than 4 letters
(regex ^\w{1,3}\b). Intersect eventually takes care of excluding the
pronouns listed above.
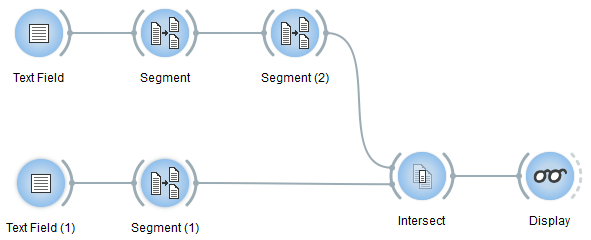
Figure 3: A possible solution.