Preprocess¶
Basic text preprocessing.
Signals¶
Inputs:
SegmentationSegmentation covering the text that should be preprocessed
Outputs:
Text dataSegmentation covering the modified text
Description¶
This widget inputs a segmentation, creates a modified copy of the content of the segmentation, and outputs a new segmentation corresponding to the modified data. The possible modifications are on the case (lower case/upper case) and the replacing of accentuated characters by their non-accentuated equivalents.
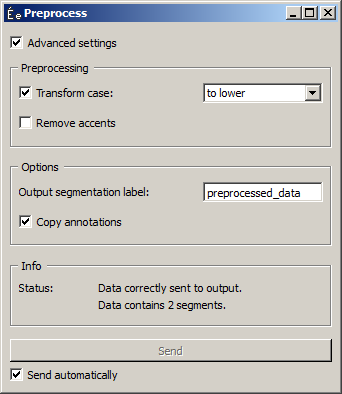
Figure 1: Interface of the Preprocess widget.
Note that Preprocess creates a copy of each modified segment, which increases the program’s memory footprint; moreover this widget can only work on segmentations without any overlap, which means no part of the text is covered by more than one segment.
In the Preprocessing section of its interface (see figure 1 above), the Transform case checkbox triggers the systematic modification of the case: select to lower to convert every character to lower case and to upper to convert them to upper case. The Remove accents checkbox controls the replacement of accentuated character by their non-accentuated equivalents (é -> e, ç -> c, etc.).
The Options section enables the user to define the label of the output segmentation (Output segmentation label). The Copy annotations button copies all the annotations of the input segmentation to the output segmentation; it is only accessible when the Advanced settings checkbox is selected (otherwise the annotations are by default copied).
The Info section indicates the number of segments present in the output segmentation, or the reasons why no segmentation is emitted (no input data, overlaps in the input segmentation, etc.).
The Send button triggers the emission of a segmentation to the output connection(s). When it is selected, the Send automatically checkbox disables the button and the widget attempts to automatically emit a segmentation at every modification of its interface or when its input data are modified (by deletion or addition of a connection, or because modified data is received through an existing connection).
Caveat¶
As one of the rare widgets of Textable that do create new strings and not only new segmentations, Preprocess is prone to a very specific and possibly disconcerting type of error, which can be best understood by studying an example.
Suppose that you wish to count word frequency in the content of two Text Field instances–a scenario similar to that illustrated in section Counting in specific contexts. You could use Merge to combine the Text Field instances’ output in a single segmentation (see figure 2 below), then segment the latter into words with Segment. You would eventually feed both the segmentation emitted by Segment (specifying units) and by Merge (specifying contexts) to an instance of Count for building the frequency table.
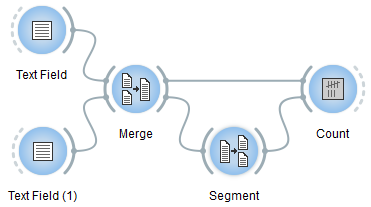
Figure 2: Counting words in the content of two Text Field instances.
Moreover, suppose that you want to convert the input texts to lower case before counting word frequency. An intuitive way of performing this is by inserting a Preprocess instance between Merge and Segment as on figure 3 below. However, because Preprocess creates a new string for each input segment and emits a segmentation that refers to these new strings, this raises a rather insidious issue.
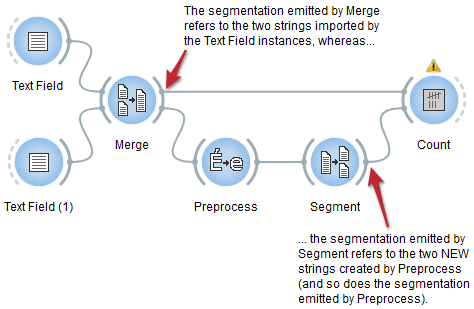
Figure 3: WRONG way of inserting a Preprocess instance in the schema.
To no effect, Count will attempt to find occurrences of the units specified by the segmentation received from Segment in the contexts specified by the segmentation received from Merge; since those actually belong to distinct strings, none of these units occurs in any of these contexts and the frequency table will remain hopelessly empty (as indicated by the warning symbol on top of the Count widget instance).
Luckily, a small wiring modification suffices to entirely solve the problem: the connection between Merge and Count should simply be replaced by a direct connection between Preprocess and Count, as on figure 4 below. This way, units and contexts refer to the same set of strings and occurrences of the ones can be properly counted in the others.
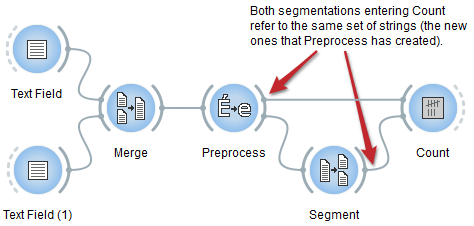
Figure 4: RIGHT way of inserting Preprocess.
Messages¶
Information¶
- Data correctly sent to output: <n> segments.
- This confirms that the widget has operated properly.
- Settings were (or Input has) changed, please click ‘Send’ when ready.
- Settings and/or input have changed but the Send automatically checkbox has not been selected, so the user is prompted to click the Send button (or equivalently check the box) in order for computation and data emission to proceed.
- No data sent to output yet: no input segmentation.
- The widget instance is not able to emit data to output because it receives none on its input channel(s).
- No data sent to output yet, see ‘Widget state’ below.
- A problem with the instance’s parameters and/or input data prevents it from operating properly, and additional diagnostic information can be found in the Widget state box at the bottom of the instance’s interface (see Warnings below).
Warnings¶
- No label was provided.
- A label must be entered in the Output segmentation label field in order for computation and data emission to proceed.
- Input segmentation is overlapping.
- At least two of the input segments cover the same substring, which this widget cannot handle. Make sure every input segment covers a distinct substring.