2.4. Counting in specific contexts¶
Section Contexts of widget Count‘s interface lets the user define the contexts in which units should be counted. Thus, while the settings of section Units affect the columns of the resulting table, those of section Contexts affect its rows.
In the example of the previous section, setting Mode to No context indicated that units were to be counted globally in the selected segmentation; as a result, the resulting table contained a single row (aside from the header row). Orange Textable offers three other modes corresponding to three different definitions of contexts.
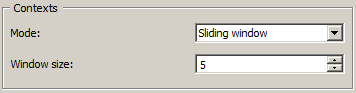
Figure 1: Interface of widget Count, Sliding window mode.
When Mode is set to Sliding window (see figure 1 above), context is defined as a “window” of n consecutive segments which “slides” from the beginning to the end of the segmentation. In the case of the letter segmentation of a simple example (as obtained with the schema illustrated in the previous section), setting the number of segments in the window (Window size) to 5 yields the following successive contexts: asimp, simpl, imple, mplee, pleex, and so on (see table 1 below). This mode is useful for studying the evolution of unit frequencies throughout a segmentation.
| a | e | i | m | l | p | s | x | |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 |
| 2 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 |
| 3 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| 4 | 0 | 2 | 0 | 1 | 1 | 1 | 0 | 0 |
| 5 | 0 | 2 | 0 | 0 | 1 | 1 | 0 | 1 |
| 6 | 1 | 2 | 0 | 0 | 1 | 0 | 0 | 1 |
| 7 | 1 | 2 | 0 | 1 | 0 | 0 | 0 | 1 |
| 8 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 |
| 9 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 |
| 10 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 |
When Mode is set to Left-right neighborhood (see figure 2), context is defined on the basis of adjacent segment types occurring to the left and/or right of each position.
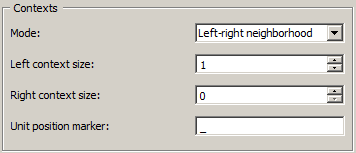
Figure 2: Interface of widget Count, Left-right neighborhood mode.
For instance, setting Left context size to 1 and Right context size to 0 amounts to counting the frequency of each segment type given the type that occurs immediately to its left. This particular table is often called “transition matrix” (see table 2 below). The string selected in the Unit position marker string is used to indicate the position where units appear in the context. Thus, table 2 shows that both m and s appear once immediately to the right of an a (i.e. in context a_). To take another example, setting Right context size to 2, we would find that e occurs once both in context l_ex and e_xa.
| a | e | i | m | l | p | s | x | |
|---|---|---|---|---|---|---|---|---|
| a_ | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| s_ | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| i_ | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| m_ | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 |
| p_ | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 |
| l_ | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| e_ | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| x_ | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Finally, when Mode is set to Containing segmentation, unit types are counted whithin the segment types of a second segmentation, as illustrated in table 2 here (frequency of letters whithin words). Segment A is considered to be contained within segment B if the following three conditions are met:
- A and B refer to the same string (their addresses have the same string index)
- A’s initial position is greater than or equal to B’s initial position
- A’s final position is lesser than or equal to B’s initial position
To try this mode out, modify the schema used in the previous section as illustrated on figure 3 below.
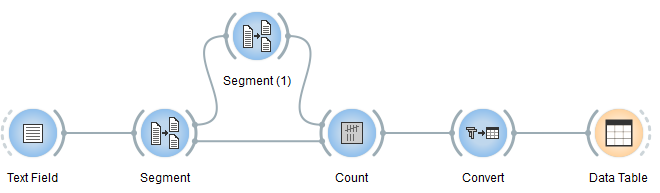
Figure 3: Schema for testing the Count widget (Containing segmentation mode).
The first instance of Segment produces a word segmentation (Regex:
\w+ and Output segmentation label: words) which the second instance
(Segment (1)) further decomposes into letters (Regex: \w and
Output segmentation label: letters). The instance of Count is
configured as shown on figure 4
below. The resulting table is the same as table 2
here (possibly with a different ordering
of columns).
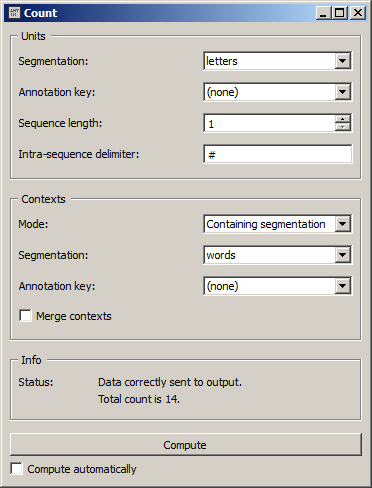
Figure 4: Configuration of widget Count for counting letters in words.
Note that in this mode, checking the Merge contexts box still restricts counting to those units that are contained whithin the segments of another segmentation, but without treating each context type separately. In the case of letters whithin words, there is no difference between this mode and mode No context (see previous section). It does however make a difference in the case of letter bigram counting, because those bigrams that straddle a word boundary will be excluded in this case (contrary to what can be seen in table 1 here).
2.4.1. See also¶
- Getting started: Counting segment types
- Getting started: From segmentations to tables
- Reference: Count widget
- Cookbook: Count unit frequency
- Cookbook: Count occurrences of smaller units in larger segments
- Cookbook: Count transition frequency between adjacent units
- Cookbook: Examine the evolution of unit frequency along the text