1.5. Segmenting data into smaller units¶
We have seen previously how to combine several segmentations into a single one. We will often be performing the inverse operation: create a segmentation whose segments are parts of another segmentation’s segments. Typically, we will be segmenting strings into words, characters, or any kind of text units that will be later counted, measured, and so on. This is precisely the purpose of widget Segment.
To try it out, create a new schema with an instance of Text Field connected to an instance of Segment, itself connected to an instance of Display (see figure 1 below). In what follows, we will suppose that the string typed in Text Field is a simple example.
Figure 1: A schema for testing the Segment widget
In its basic form (i.e. with Advanced settings unchecked, see figure 2 below), Segment takes a single parameter (aside from the Output segmentation label), namely a regex. The widget then looks for all matches of the regex pattern in each successive input segment, and creates for every match a new segment in the output segmentation.
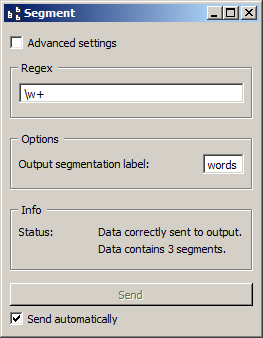
Figure 2: Interface of the Segment widget, configured for word segmentation
For instance, the regex \w+ divides each incoming segment into sequences
of alphanumeric character (and underscore)–which in our case amounts to
segmenting a simple example into three words. To obtain a segmentation
into letters (or to be precise, alphanumeric characters or underscores),
simply use \w.
Of course, queries can be more specific. If the relevant unit is the word,
regexes will often use the \b anchor, which represents a word boundary.
For instance, words that contain less than 4 characters can be retrieved
with \b\w{1,3}\b, those ending in -tion with \b\w+tion\b, and the
inflected forms of retrieve with \bretriev(e|es|ed|ing)\b.