Context¶

Explore the context of segments.
Signals¶
Inputs:
Segmentation(multiple)Segmentation containing the “key segments” whose context will be examined or the segments which serve to define these contexts.
Outputs:
Textable tableTable displaying the concordance of key segments or their collocations.
Description¶
This widget inputs one or several segmentations and outputs concordances or collocation lists in table format, allowing the user to examine the contexts in which selected segments appear.
The functioning of this widget lies on the notions of units and contexts, as all table contruction widgets. The role of the unit segmentation is central; it defines the key segments whose contexts can be examined by means of the resulting concordances or lists of collocations.
To take a simple example, consider two segmentations of the string a simple example [1]:
- label = words
| content | start | end | part of speech | word category |
|---|---|---|---|---|
| a | 1 | 1 | article | grammatical |
| simple | 3 | 8 | adjective | lexical |
| example | 10 | 16 | noun | lexical |
- label = letters (extract)
| content | start | end | letter category |
|---|---|---|---|
| a | 1 | 1 | vowel |
| s | 3 | 3 | consonant |
| i | 4 | 4 | vowel |
| ... | ... | ... | ... |
| e | 16 | 16 | vowel |
The simplest case is when a single segmentation is considered; the only way to define contexts is thus in terms of a given number of neighboring segments. For example, given the single letters segmentation, we can build the following concordance:
| __id__ | __pos__ | 1L | __key_segment__ | 1R |
|---|---|---|---|---|
| 1 | 1 | — | a | s |
| 2 | 2 | a | s | i |
| 3 | 3 | s | i | m |
| 4 | 4 | i | m | p |
| 5 | 5 | m | p | l |
| 6 | 6 | p | l | e |
| 7 | 7 | l | e | e |
| 8 | 8 | e | e | x |
| 9 | 9 | e | x | a |
| 10 | 10 | x | a | m |
| 11 | 11 | a | m | p |
| 12 | 12 | m | p | l |
| 13 | 13 | p | l | e |
| 14 | 14 | l | e | — |
In this table, the column __id__ gives the index of each key segment (its position in the table). The column __pos__ indicates the position of each key segment in the unit segmentation, and in this case this information duplicates the previous one (we will see below that it is not always the case). The key segment itself appears in the __key_segment__ column, and its direct neighbors on the left and the right appear respectively in the columns 1L and 1R.
The number of neighbors shown on the left and right can of course be higher, just as we can show the annotation values instead of the segment contents (be it key segments or their neighbors). For example, the following table gives 2 direct neighbors of each letter by showing their annotation value for the key letter category:
| __id__ | __pos__ | 2L | 1L | __key_segment__ | 1R | 2R |
|---|---|---|---|---|---|---|
| 1 | 1 | — | — | a | consonant | vowel |
| 2 | 2 | — | vowel | s | vowel | consonant |
| 3 | 3 | vowel | consonant | i | consonant | consonant |
| 4 | 4 | consonant | vowel | m | consonant | consonant |
| 5 | 5 | vowel | consonant | p | consonant | vowel |
| 6 | 6 | consonant | consonant | l | vowel | vowel |
| 7 | 7 | consonant | consonant | e | vowel | consonant |
| 8 | 8 | consonant | vowel | e | consonant | vowel |
| 9 | 9 | vowel | vowel | x | vowel | consonant |
| 10 | 10 | vowel | consonant | a | consonant | consonant |
| 11 | 11 | consonant | vowel | m | consonant | consonant |
| 12 | 12 | vowel | consonant | p | consonant | vowel |
| 13 | 13 | consonant | consonant | l | vowel | — |
| 14 | 14 | consonant | consonant | e | — | — |
The particularity of such tables is that they give the context of every segment of the single considered segmentation. In general, we are rather interested in certain specific segments, which we can indicate by means of a distinct segmentation. Supposing that we have, in addition to the letters segmentation, a segmentation whose label is key_segments and that contains only the occurrences of letter e (always in the string a simple example): [2]
| content | start | end | letter category |
|---|---|---|---|
| e | 8 | 8 | vowel |
| e | 10 | 10 | vowel |
| e | 16 | 16 | vowel |
By specifying the key segments with this segmentation and the contexts (here the neighboring segments) with the letters segmentation, we can then produce the following table:
| __id__ | __pos__ | 2L | 1L | __key_segment__ | 1R | 2R |
|---|---|---|---|---|---|---|
| 1 | 7 | consonant | consonant | e | vowel | consonant |
| 2 | 8 | consonant | vowel | e | consonant | vowel |
| 3 | 14 | consonant | consonant | e | — | — |
This example of a more typical concordance proves, for that matter, that the position of the key segment in the table (column __id__) is not necessarily equal to its position in the segmentation that defined the contexts (column __pos__).
In the previous examples, the context of each key segment is defined in the terms of the neighboring segments in a segmentation. Another possibility is to define the context on the basis of another segmentation whose segments contain the key segments. To illustrate this second mode of context characterization, consider the case where units are specified by the key_segments segmentation, as previously, and the contexts by the words segmentation:
| __id__ | __pos__ | __left__ | __key_segment__ | __right__ |
|---|---|---|---|---|
| 1 | 2 | simpl | e | — |
| 2 | 3 | — | e | xample |
| 3 | 3 | exampl | e | — |
This example shows the implications of this change of context specification mode. Firstly, the resulting table now has a fixed width [3] of 5 columns: __id__ and __key_segment__ have the same function as before; __pos__ indicates the position of the context segment that contains each key segment (which allows the user to find and view the context in question with the Display widget); finally the columns __left__ and __right__ respectively give the left and right part of each context segment containing a key segment.
Moreover in this case, replacing the segment content with one of its annotation values would not make much sense. However, it can be useful to indicate such a value in a separate column, as part of speech in the following example which also illustrates the possibility of replacing the content of the key segment with an annotation value (here letter category):
| __id__ | __pos__ | __left__ | __key_segment__ | __right__ | part of speech |
|---|---|---|---|---|---|
| 1 | 2 | simpl | vowel | — | adjective |
| 2 | 3 | — | vowel | xample | noun |
| 3 | 3 | exampl | vowel | — | noun |
These examples highlight the versatility of the Context widget, whose possibilities are more diverse than those a basic concordancer typically offers – at the cost of a more complex application since it generally involves being able to build and put in relation two or more distinct segmentations of the analyzed text.
We conclude this overview of the capacities of the widget with the building of collocation lists. First note that this functionality is here conceived as a visualization option applicable to a concordance where the context is defined in terms of the neighboring (rather than containing) segments. Instead of representing the neighboring segments of each key segment occurrence, we can in fact build a list of these (types of) segments with an indication of the attraction or on the contrary repulsion between each of them and the key segment.
Consider again the example of the concordance presented earlier where the units are given by the key_segments segmentation and the context by the letter category annotations values of the letters segmentation:
| __id__ | __pos__ | 2L | 1L | __key_segment__ | 1R | 2R |
|---|---|---|---|---|---|---|
| 1 | 7 | consonant | consonant | e | vowel | consonant |
| 2 | 8 | consonant | vowel | e | consonant | vowel |
| 3 | 14 | consonant | consonant | e | — | — |
The same data enable the program to produce the following collocation list:
| __unit__ | __mutual_info__ | __local_freq__ | __local_prob__ | __global_freq__ | __global_prob__ |
|---|---|---|---|---|---|
| consonant | 0.292781749228 | 7 | 0.7 | 8 | 0.571428571429 |
| vowel | -0.51457317283 | 3 | 0.3 | 6 | 0.428571428571 |
The column __mutual_info__ gives the mutual information (in bits) between the key segment (here the letter e) and each value of the letter category annotation that appeared close by (here at a maximum distance of 3 segments) the key segments. This quantity is the binary logarithm of the ratio of the probability of the letter category value in question close to the key segment and its probability in the context segmentation in general.
Thus the consonant type appears 7 times in the surroundings of e (__local_freq__), on a total of 10 segments that appeared close, hence the “local” probability of 7/10 = 0.7 (__local_prob__); moreover the same type appeared 8 times in the whole letters segmentation (__global_freq__), on a total of 14 segments, hence the “global” probability of 8/14 = 0.57 (__global_prob__). Finally the binary logarithm of 0.7/0.57 = 1.22 is 0.3 bits (__mutual_info__), and this (slightly) positive value reflects the (weak) attraction between e and the consonant type at a maximum distance of 3 segments. Conversely, the negative mutual information between e and vowel shows that these categories are in a rather repulsive relation in the considered surrounding.
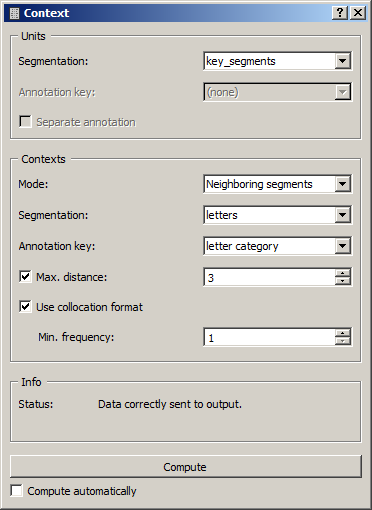
Figure 1: Interface of the Context widget.
The widget interface (see figure 1) is divided in two separate sections of unit specification (Units) and context specification (Contexts). In the Units section, the Segmentation drop-down menu allows the user to select among the input segmentations the one whose segments will play the role of key segments. The Annotation key menu shows the potential annotation keys associated to the chosen segmentation; if one of the keys is selected the corresponding annotation values will be used; if on the other hand the value (none) is selected, it will be the content of the segments. The Separate annotation button, activated only when an annotation key is selected, enables the user to indicate that the values associated to this key must appear in a separate column (whose header is the corresponding key) rather than replace the segment contents in the column __key_segment__. Note that the two buttons (Annotation key and Separate annotation) are disabled when the button Use collocation format is selected.
In the Context section, the Mode menu allows the user to choose between the two context characterization modes mentioned earlier: in terms of neighboring segments of the key segment (Neighboring segments) or of segments containing them (Containing segmentation). In both cases, the segmentation in question is selected among the input segmentation through the Segmentation drop-down menu and the Annotation key menu shows the potential annotation keys associated to this segmentation. If one of these keys is selected, the display of the corresponding values varies depending on the Mode used: in Neighboring segments mode, the annotation values replace the content of the segments in the columns 1R*, 1L, ... ; in Containing segmentation mode, they appear in a separate column whose header is the corresponding annotation key.
In Neighboring segments mode, the Contexts section also allows the user to indicate if a limit should be set to the number of neighboring segments shown for each key segment and where it is set (Max. distance). The Use collocation format button is used to format the result as a collocation list (rather than a concordance); when it is selected, the Min. frequency drop-down menu allows the user to specify the (global) minimal frequency that the segment type must reach in order to appear in the list.
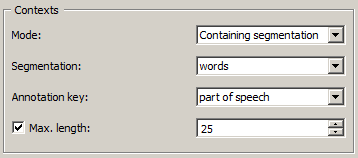
Figure 2: Context widget (Containing segmentation mode).
In Containing segmentation mode (see figure 2), the Contexts section allows the user to specify the maximal number of characters that appear in the right and left context of the pivot.
The Info section indicates if a table was correctly emitted, or the reasons why no table is emitted (typically, because it is empty).
The Compute button triggers the emission of a table in the internal format of Orange Textable, to the output connection(s). When it is selected, the Compute automatically checkbox disables the button and the widget attempts to automatically emit a segmentation at every modification of its interface or when its input data are modified (by deletion or addition of a connection, or because modified data is received through an existing connection).
Messages¶
Information¶
- Data correctly sent to output.
- This confirms that the widget has operated properly.
- Settings were (or Input has) changed, please click ‘Compute’ when ready.
- Settings and/or input have changed but the Compute automatically checkbox has not been selected, so the user is prompted to click the Compute button (or equivalently check the box) in order for computation and data emission to proceed.
- No data sent to output yet: no input segmentation.
- The widget instance is not able to emit data to output because it receives none on its input channel(s).
- No data sent to output yet, see ‘Widget state’ below.
- A problem with the instance’s parameters and/or input data prevents it from operating properly, and additional diagnostic information can be found in the Widget state box at the bottom of the instance’s interface (see Warnings below).
Warnings¶
- Resulting table is empty.
- No table has been emitted because the widget instance couldn’t find a single element in its input segmentation(s). A likely cause for this problem (when using the Containing segmentation mode) is that the unit and context segmentations do not refer to the same strings, so that the units are in effect not contained in the contexts. This is typically a consequence of the improper use of widgets Preprocess and/or Recode (see Caveat).
See also¶
Footnotes¶
| [1] | By convention, we do not indicate here the string index associated with each segment but only its start and end positions, along with the various annotation values associated with it; moreover, for the sake of readability, we do indicate the content of each segment, though it is not formally part of the segmentation (but rather of the string to which the segmentation refers). |
| [2] | It is typically by means of the Select widget that we could produce such a segmentation. |
| [3] | Except in the “pathological” case where no key segment is contained in the context segment. |